socket服务启动之后过一会就会出现客户端不能连接的情况,什么原因导致的呢?

问题描述
socket服务启动之后过一会就会出现客户端不能连接的情况,什么原因导致的呢?
还有就是现在服务器一直收到 ping 请求,有的一个用户在同一秒发送了七八次ping

还有问题就是connections的值一直在增长,但是并没有那么多用户,现在用户量最多同时在线几百
memory也是一直增长。
之前项目运行的好好的,后来用户多了一点之后就会出现有的用户收不到socket消息,不知道用户是否重连没有重新进组还是什么。
1369 1 2
1个回答
相似问题
年代过于久远,无法发表回答






workerman手册有说,单个进程连接数超过1000的话需要安装event扩展
php -m|grep event查看是否安装吗?如果不安装event会导致哪些后果?
php -m| grep event可以看php是否安装event扩展。
php start.php status 里显示 event-loop:\Workerman\Events\Event 则是启用。
不装event扩展当连接数超过1000时,超过的部分将无法收到消息,无法检测到连接断开等事件,导致连接数增多,消息收不到或延迟,内存增大。
项目是运行在docker容器里的。优化Linux内核是优化宿主机还是容器的?
客户端A和B链接成功之后加入一个组,我后端服务重启之后,客户端B发送组内消息 客户端A出现消息延迟这种什么情况?
保险起见linux内核都优化下。
延迟问题根据你提供的信息无法判断延迟原因,可能是业务有什么耗时操作导致延迟,也可能是没装event扩展连接数超过1000限制导致的延迟
一个问题一个问题的解决
event安装了 收不到消息、内存、连接数这些目前没发现问题,connections也降下来了。
现在就是客户端和服务器端都设置了10秒进行心跳检测。服务器10发送给客户端。客户端10秒给服务器发送心跳检测。但是现在打日志看到同一个用户在同一秒内能发送10个左右的心跳检测,这种是客户端导致的吗?但是当那个用户重新链接之后就是10秒一次了
客户端问题
postman收到的那就是服务端发的
客户端显示发送了,过了几秒在Gateway 的自定义Events里onMessage里才接收到,中间这几秒异常怎么查呢?
是客户端发送失败还是网络延迟或者是后端workerman处理时卡到哪里了?
onMessage里记录下总的执行时间,看下是不是业务哪里太慢了
onMessage记录总时间包括wokerman处理链接的时间吗?就像nginx代理API那样,PHP能记录nginx执行时间吗?
现在是onMessage收到之后能很快就返回结果,但是在客户端点击发送到onMessage收到消息中间会出现延迟,不知道是客户端的问题还是网络问题或者服务端workerman问题,这种怎么查证????
onMessage 是收到消息触发的,不包括之前消息接收时间。
你可以尝试把nginx去掉试下排除nginx问题,暂时去掉所有业务排除业务问题。
我直接通过端口启动的,然后通过域名加端口访问的时候还是要先走nginx解析域名的是吧?但是我客户端建立socket链接之后每次发送消息还要再走nginx解析吗?中间这块的时间不应该是workerman的解析吗?
域名加端口不走nginx,除非端口是nginx端口
既然不走nginx。那现在情况是 客户端执行send之后到我gateway Events的onMessage第一次输出日志,有时候中间的时间会是十几秒,这种怎么查?是网络问题还是服务端workerman服务问题?
可能是有慢业务影响,所以让你去掉所有业务试下。或者下载一个workerman-chat试下
没法去掉。只有正式环境才会有延迟,也不是一直有,就是当人多起来的时候会出现。
打了日志,进入onMessage的时候记录开始时间[毫秒] 然后在业务处理完之后做日志记录减去开始时间就没有大于20毫秒的。但是在使用的时候确实还是出现卡顿,还有什么办法查证吗?
event扩展确认安装成功,带宽足够
之前客户端有些问题会创建一堆的连接,现在做的客户端做的心跳检测是10秒一次,但是我服务器收到的是有一大批都是每个连接每秒好几次ping事件。这些ping事件多了即使业务处理的快也会造成一定的堆积,business处理不过来导致卡顿吧?
安卓创建socket连接,当出现断网或者异常的时候socket连接会重新创建,但是之前的socket连接没有销毁,不管是之前的还是新的连接用的都是同一个变量名,然后当网络连接恢复的时候就客户端会出现触发很多次的onopen,是不是意味着断网的时候创建的那些socket又活过来了,然后这些socket还能正常发送请求?用的是不是还是同一个clientid?
处理ping没有什么业务逻辑,一般都很快,应该不是ping造成的。看下服务器带宽
是不是一个clientid可以自己打日志看
客户端onopen打开的时候不是同一个clientid
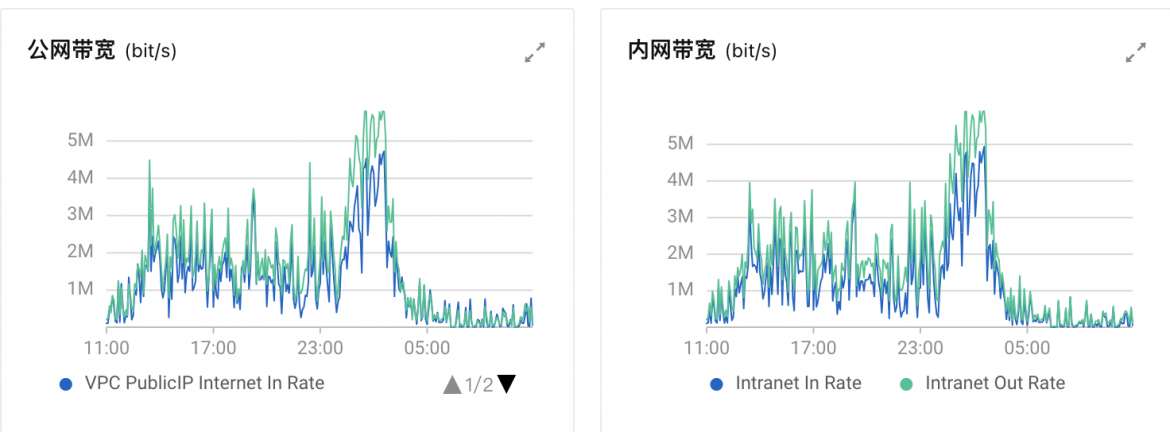
带宽图放上去了,目前5M的带宽。但是之前的时候带宽都是在4以下
出现卡顿的时候看下实时带宽,你截图的是被整体平均过的。
图中出方向的带宽超过5M了,目前来看是不是需要增加带宽了?
带宽不够出现卡顿很正常
就目前的话,增加带宽增加到多少合适?同时在线用户数多的时候也不到1000
你看监控里大概需要多少就设置多少
不是说上图的是被整体平均过的吗,那也就是说有的肯定要比图中的要高?那增加的时候应该要比图中的要高出一部分吧
对
出的带宽使用多少其实也是与我服务器返回内容大小有关吧,我返回的数据少了占用的就少
对