webman-admin统计行数过慢

问题描述
一张表大约1200w数据,使用mysql的SELECT COUNT(*) FROM 数据表;大约耗时40秒
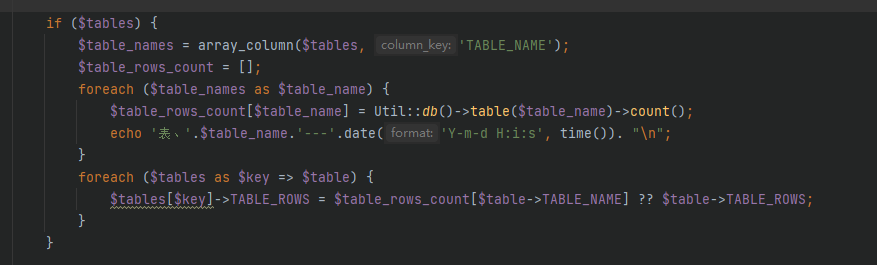
查看webman-admin源码,发现Table控制器下的show方法执行到如下查询很缓慢。有什么办法优化吗?
为此你搜索到了哪些方案及不适用的原因
count(*) :它会获取所有行的数据,不做任何处理,行数加1。
count(1):它会获取所有行的数据,每行固定值1,也是行数加1。
count(id):id代表主键,它需要从所有行的数据中解析出id字段,其中id肯定都不为NULL,行数加1。
count(普通索引列):它需要从所有行的数据中解析出普通索引列,然后判断是否为NULL,如果不是NULL,则行数+1。
count(未加索引列):它会全表扫描获取所有数据,解析中未加索引列,然后判断是否为NULL,如果不是NULL,则行数+1。
由此,最后count的性能从高到低是:
count(*) ≈ count(1) > count(id) > count(普通索引列) > count(未加索引列)
766 1 1
1个回答
相似问题
年代过于久远,无法发表回答






目前只能临时把它屏蔽了。
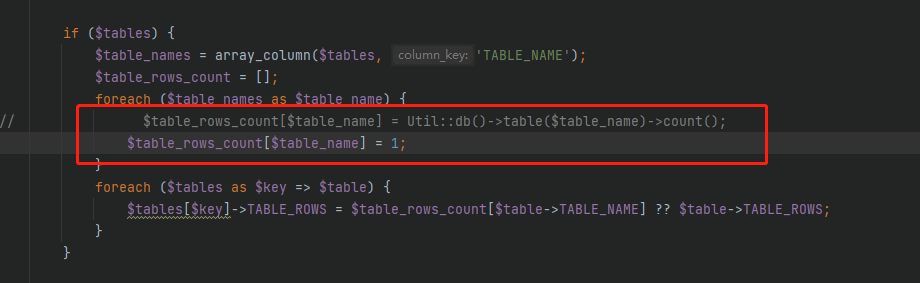
如果你的mysql表是从1开始自增。并且中途没有数据的删除跟丢失的话,可以用 max(id)。但这样做法其实不对,我们的表就有中途丢失数据的情况,统计超过1千万的表的rows行数 建议记录在redis里面,每次新增数据后 incrby一次。之前我处理大表的时候就是这样做的,可以参考一下