tcp突然升高,重启tcp无效,重启服务器才可以?
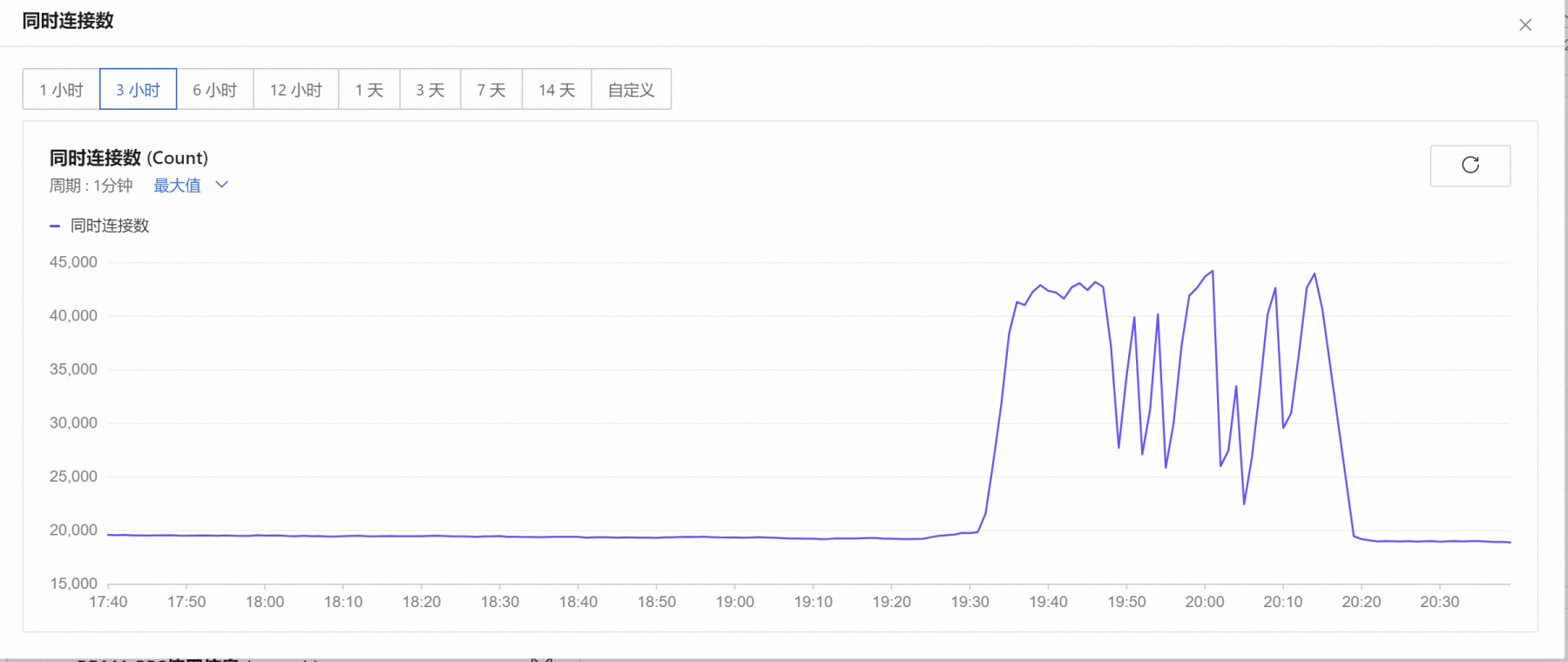
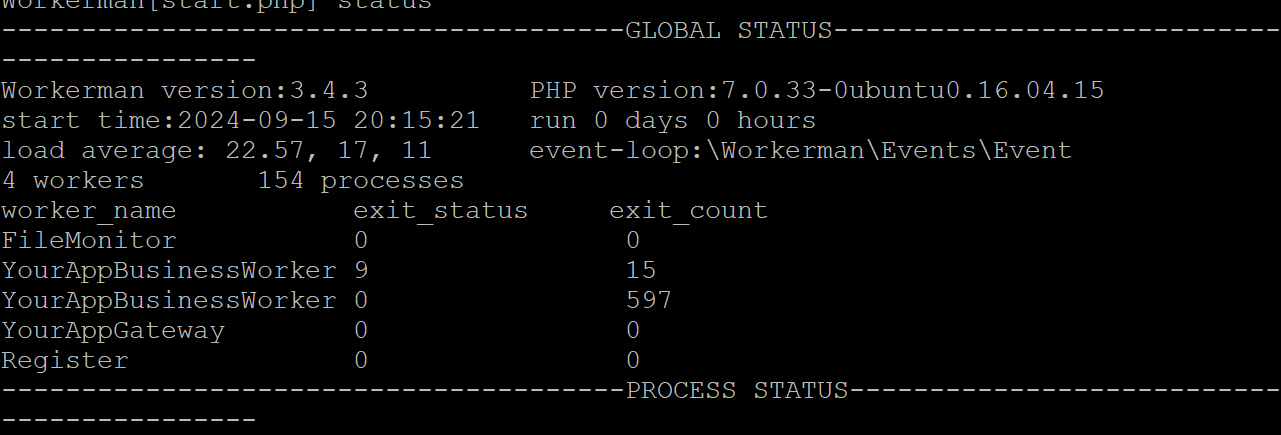
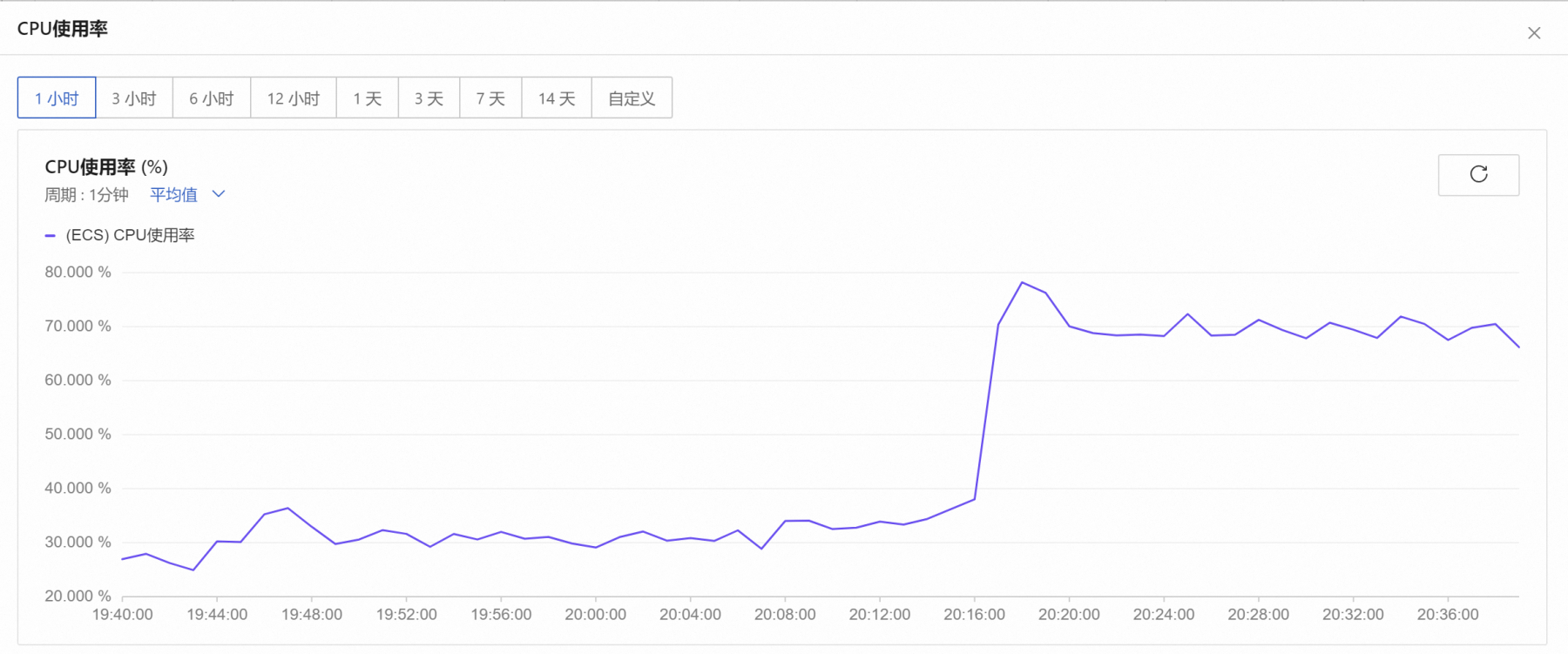
今晚阿里云监控突然报警,tcp连接数突然暴涨,从两万升到四万左右,以前都是重启tcp就可以了,但是今晚重启无效,然后增加了gateway和bussinessworker,以daemon模式启动后,并执行php start.php reload,刚开始出现了一个bussinessworker进程,但是再次用status查看的时候又没有了,一直重复reload都没有效果,期间不断的增大gateway和bussinessworker数量,然后重启,但是都没有效果,大概这样操作了半个小时,但是bussinessworker一直起不来,最后重启了整个服务器,然后启动gateway,这个时候bussinessworker终于起来了,设备可以正常连上了,但可能是因为我这边把gateway设置的太高了,现在cpu比较高,服务器cpu是4核的,gateway设置了32现在,bussinessworker120,应该是gateway设置太高的原因。虽然进程起来了,但是status指令查看的时候,出现了两条bussinessworker记录,其中一个显示exit_status:9,这是为什么?
还有为什么重启tcp无效,重启服务器就正常了?
截图报错信息里报错文件相关代码
528 1 0
1个回答
相似问题






https://www.workerman.net/q/13202
相关原因之前分析过了。exit_status:9 就是业务处理太慢,reload时一直没响应被kill掉了。
还有gateway进程太多太多了,一台服务器2个gateway就好。
businessWorker进程一直都在,只是你业务太慢无法及时响应无法展示,建议升级下workerman。
1、之前这个系统,我们发现tcp突然飙升之后,都是通过重启tcp来稳定系统的,这个方法一直有效,今天却突然失效了,不知道是为什么?
2、我们使用gatewayworker挺久了,内核优化也做了,但是系统偶尔还是会出现tcp突然暴涨的情况,之前一直都是通过重启tcp来解决的,系统为什么会运行好好的突然就tcp暴涨呢?
3、升级workerman的可以解决这些问题吗?是直接下载https://github.com/walkor/GatewayWorker?tab=readme-ov-file这个版本吗?
通过命令 composer require workerman/workerman 升级workerman
连接数为什么增长需要自己排查出原因,截图看不出什么。
重启gatewayWorker 连接数不下降可能是因为连接是timewait连接,timewait连接由linux内核管理,时间到了会自动消亡,不用处理。
通过这个命令能统计出各个状态的连接,正常的时候记录下各个端口各个状态连接数多少。异常的时候记录下,对比下哪个端口哪个状态的连接增加了。
netstat -ant | awk '{print $6, $4}' | grep -v '^State' | awk '{split($2, a, ":"); print $1, a[length(a)]}' | sort | uniq -c | sort -nr | head -50我去官网下载了workerman,和我现在用的gatewayworker不太一样,gatewayworker也是用https://github.com/walkor/workerman这个代码包吗?重启gatewayWorker的时候bussinessworker一直busy,但是重启服务器后就好了这是为什么?
https://www.workerman.net/doc/workerman/debug/busy-process.html
这里有调试busy进程的教程
net.ipv4.ip_local_port_range手册上建议是10240 65000,我这边设置成20000 65000有影响吗
影响不大,建议按照手册配置
linux执行netstat -ant | awk '{print $6, $4}' | grep -v '^State' | awk '{split($2, a, ":"); print $1, a[length(a)]}' | sort | uniq -c | sort -nr | head -50提示illegal reference to array a
装一下gawk, length(a)是gawk的语法
装了gawk上面的命令不用改,系统会自动用gawk替代原有awk