gateway进程cpu跑满,报错
问题描述 两台部署的gatewayworker服务,硬件配置为16核32G,最近半个月经常出现一台机器上的几个gateway进程cpu跑满100%,导致业务无法正常转发。 故障时status信息如下: worker进程显示不出来 通过strace -ttp 异常进程,得到的信息如下 另外开启了框架调试日志,输出的结果如下172.17.201.188是本机内网ip: ...
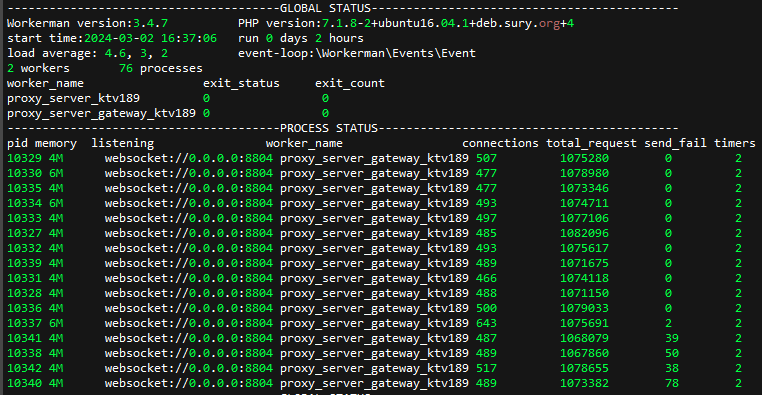
压力测试GatewayWorker的并发连接结束后,其中一个gateway进程cpu一直长期100%
问题描述 生产环境是2台16核32G的配置,按照手册分布式部署,配置gateway进程16个,和worker进程数100个, 使用压力测试系统并发2000个链接,只链接,不发送业务处理。在压力测试下,gateway进程cpu个别跑满,其他的也大都在70%,压力测试关掉后很长一段时间,有一个gateway进程cpu始终100%,其他gateway进程cpu基本回落到0,该状态下,业务系统可以正常链接上gateway,但...
gatewayworker分布式部署扩容后的性能问题
目前按照分布式的方式部署了2台gatewayworker,每台开30个gateway进程,100个bussinessworker进程(16核32G,云服务商主机),注册中心放在其中一台上面,上周两台服务器cpu由于业务增长,cpu达到了50%,cpu的sy指标都高于us,差不多是us的两倍,为了应付后续的业务增长,增加部署了两台(8核16G),但是发现对之前2台的cpu都没有起到降低作用,基本没有变化。实在是搞不懂这...
WORKER EXIT UNEXPECTED exit with status 64000
服务运行一段时间后就会出现一下错误,然后其他第三方服务发送给gatawayworker的数据就收不到返回了,这种情况下要如何排查: 2017-01-07 16:07:52 Workerman status 2017-01-08 13:53:22 WORKER EXIT UNEXPECTED 2017-01-08 13:53:24 worker exit with status 64000 2017-01-08 13:...
gatewayworkerman 分布式部署后,个别终端通信异常
1.gatewayworkerman 目前是分布式部署,部署2台,作为通讯中讯服务,然后入口是一台负载均衡服务器,会自动代理链接分发到2台任意一台。 程序逻辑大致如下: onMessage(clientid,message) { (1)记录message消息进入文件日志 logger(message); //产生问题,继续往下看完 (2)判断数据包类型...
php cpu占用图片飙升降不下来,日志显示worker[proxy_server:1743] exit with status 64000
目前使用gatawayworker搭建了一个名为proxy_server的服务,主要就是数据转发而已,没有涉及什么数据库等东西。目前并没有找到什么规律,有时候从进程里看到php的cpu占用非常高,每个php进程都到了80-95的占用。重新启动 gatawayworker服务可以恢复正常状态。现在看日志也不知道是哪里的原因,只看到日志里有以下记录: 2016-11-14 21:43:16 WORKER EXIT UNE...